Blogs
Insights & Updates
Stories on AI-native learning, product updates, and the future of education without friction.
Stories on AI-native learning, product updates, and the future of education without friction.
You know the drill.
You find a paper, a video, or a tutorial that finally makes something click. You open a terminal, spin up a notebook, and type pip install. Forty-five minutes later you are still debugging a CUDA version mismatch, the dataset URL returns a 404, and the learning window has slammed shut.
This is tutorial hell. And it is not a you problem, it is an infrastructure problem.
Last Lab was built to end it.
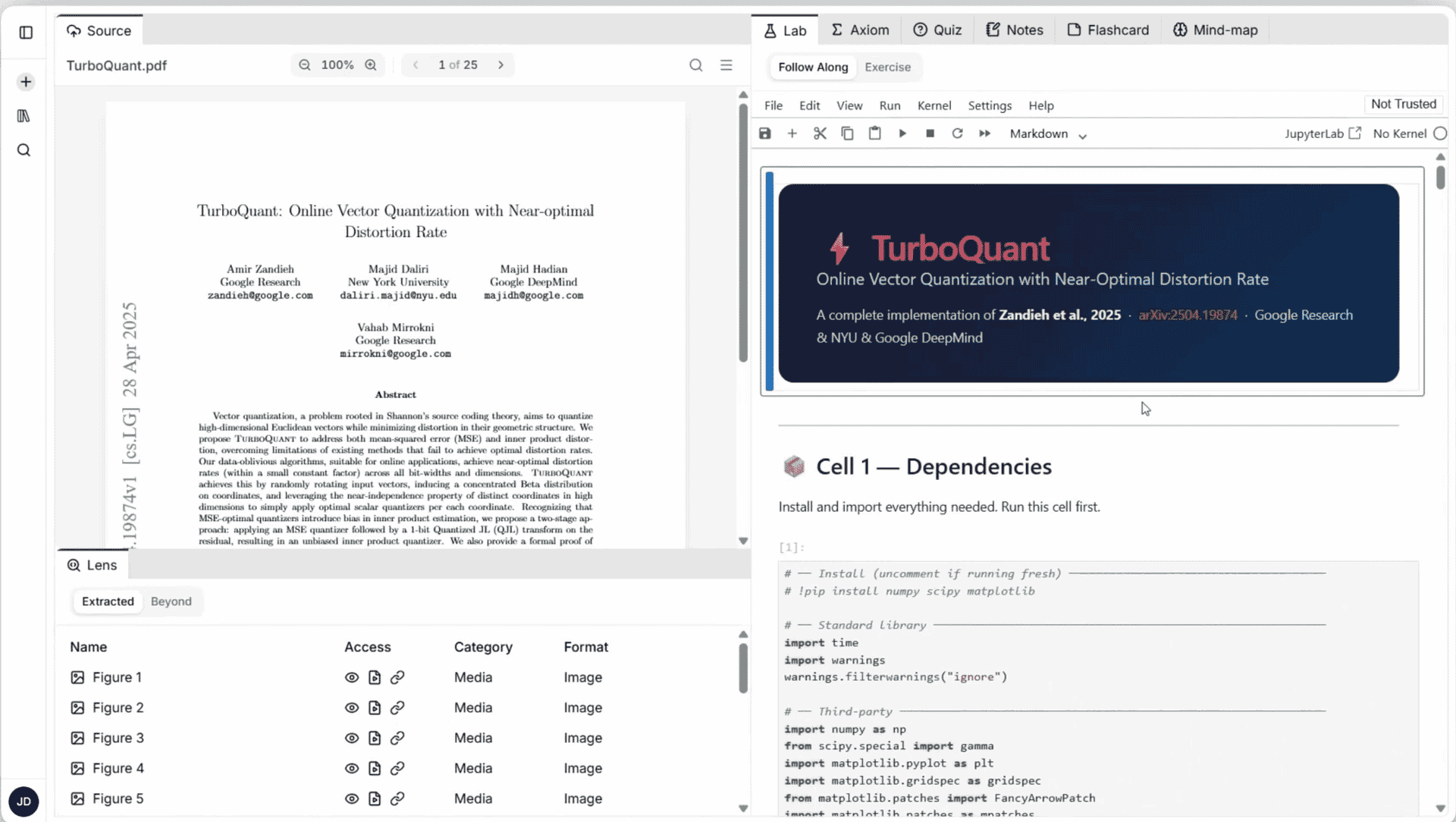
Last Lab is an AI-native learning platform that transforms any learning resource - a YouTube video, a research paper, a GitHub repository, a blog post, a PDF, into a fully executable, interactive learning environment.
Paste a URL or upload a file. In seconds, you get a running Jupyter notebook, contextual AI assistance, quizzes, flashcards, mind maps, and extracted resources, all grounded in exactly what you uploaded. No extra tabs. No environment configuration. No copy-pasting code from five different places.
One input. One environment. Everything you need to go from passive understanding to actually building, in the same place, at the same time.
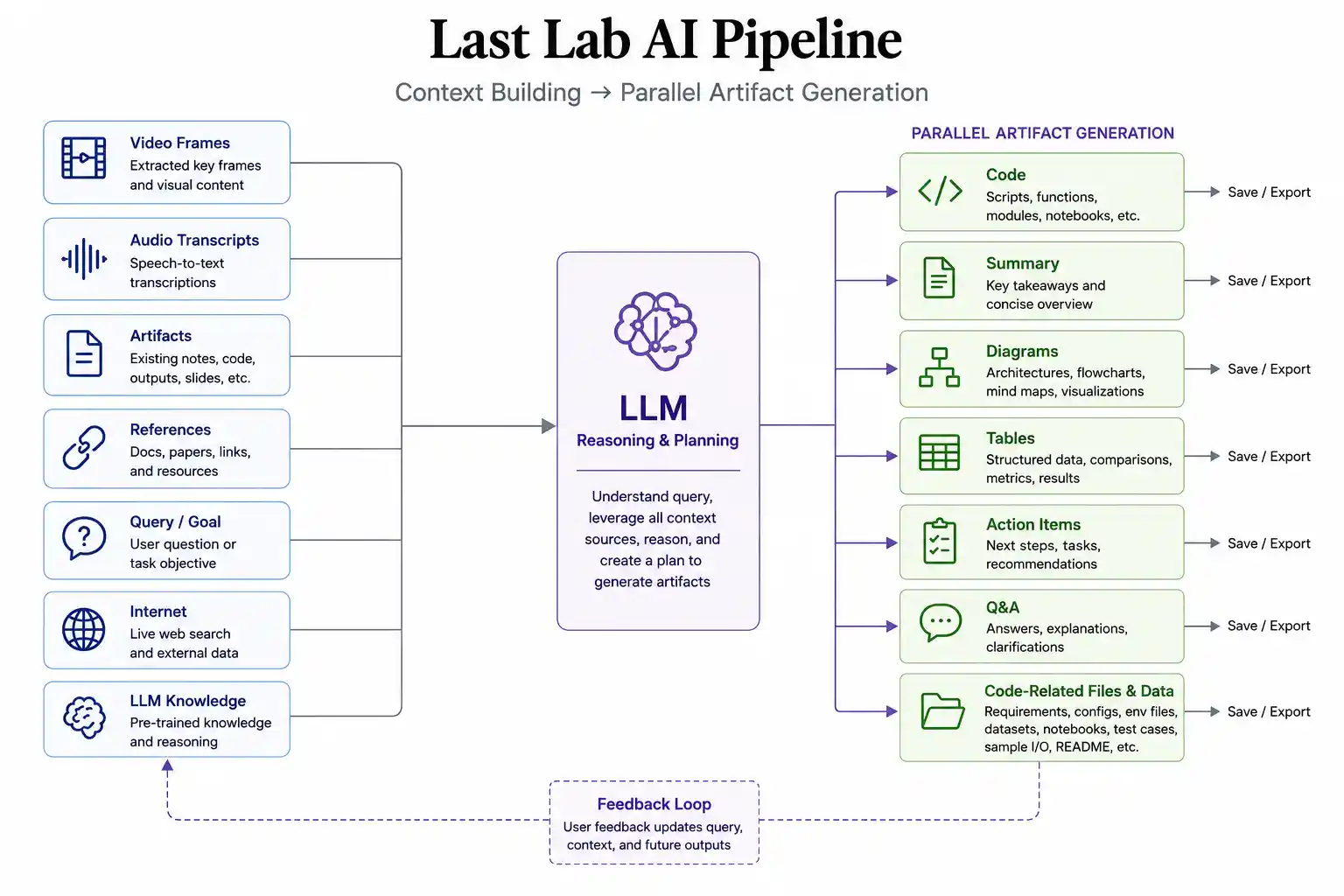
The moment you submit a resource, Last Lab’s agentic AI pipeline fires.
For a YouTube video, a Vision-Language Model watches every frame, not just the transcript. It extracts diagrams drawn on whiteboards, code shown on screen, flowcharts, and structured notation that never appears as text. In parallel, a sub-agent resolves everything referenced in the description: GitHub repos, datasets, linked papers, pulled in, processed, and incorporated into the context.
For a research paper, the pipeline handles what every other tool fails on: LaTeX equations, complex tables, and structured algorithmic notation are extracted correctly and used as the implementation blueprint. This matters especially on limited compute, where a single hallucinated matrix dimension means hours of wasted GPU time.
Once context is built, everything downstream generates in parallel: the notebook, quizzes, flashcards, mind maps, and AI tutor are all loaded simultaneously. You wait once. Everything is ready together.
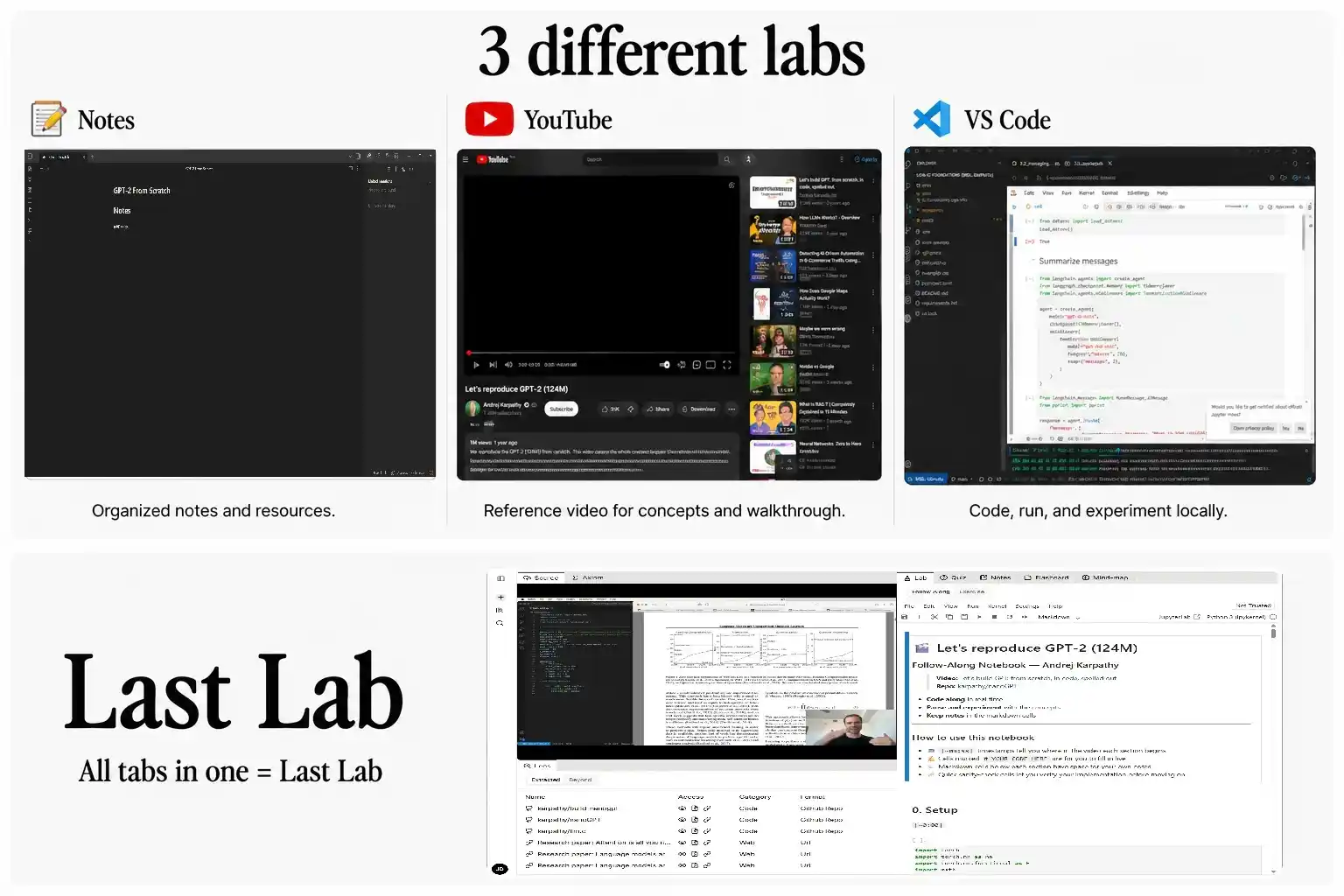
Every LLM today can write a Jupyter notebook. Last Lab runs it. That distinction is everything.
Every notebook arrives with dependencies pre-installed, the execution environment pre-configured, and the kernel ready. You press run on cell one, and it works. No venv. No package hell. No works-on-my-machine.
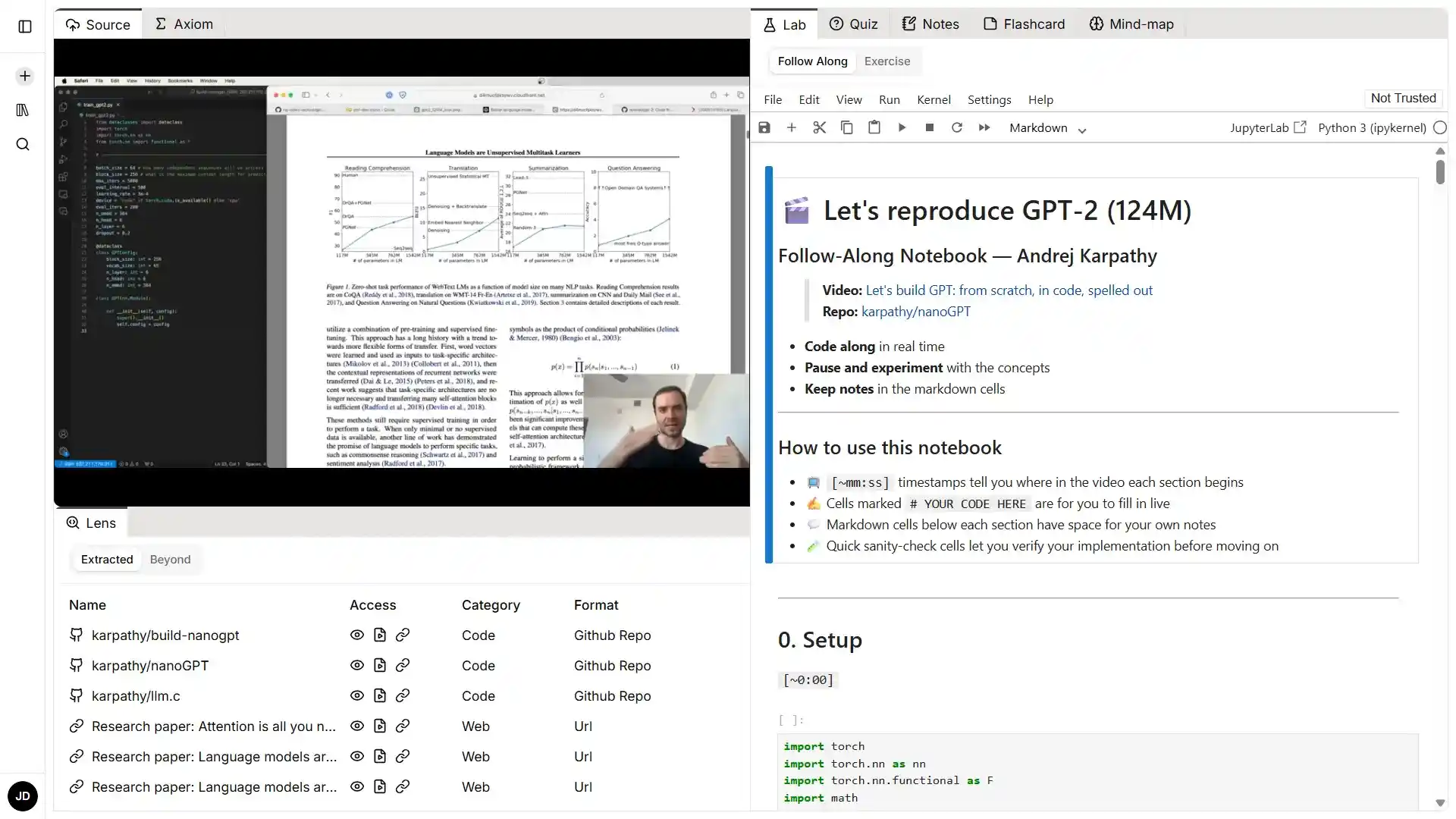
Follow-Along Labs mirror the resource exactly, code pre-filled, boilerplate handled, environment set. You follow the material without managing a single dependency.
Exercise Labs flip the model. Only the instructions exist. You solve it. Up to two hints are available before the answer is revealed. Test cases validate and score your work.
Iterative Learning Mode rebuilds the same concept from scratch, layer by layer. Learning backpropagation? Iteration one: write the gradient formula directly. Iteration two: decompose it into primitive operations and compose them. Building a game with tkinter? Iteration one sets up the GUI. Iteration two adds the snake. Each pass deepens understanding instead of just advancing the syllabus.
Most AI assistants in education are glorified copy-paste interfaces. You describe your problem, strip out the context that does not survive plain text, and hope the AI fills the gap. It usually does not.
Axiom is different. It lives inside your learning session with full visibility into everything: the video frame you are watching, the notebook cell you are in, the quiz question you are stuck on. And critically, you do not describe what you are looking at. You select it.
Marquee-select a frame from a running video and ask about it. Highlight a LaTeX equation in a research paper and ask about it. Point at a node in a mind map, a cell in the lab, or a line in extracted resources. Axiom receives the selection with full visual and session context and answers from it. Nobody in ed-tech does this. Not even close.
Axiom runs in two modes. Scoped mode grounds every answer strictly in your uploaded resource, keeping the learning anchored to a single consistent source, with no notation conflicts from other authors bleeding in. Beyond mode opens Axiom to its full knowledge when the resource leaves gaps you need filled.
The lab is the core. But Last Lab is a full environment.
Resources (Lens) extracts every artifact from your content, diagrams with timestamp citations, datasets, referenced papers, linked repos, and resources mentioned verbally but never linked. If a concept is only partially covered, Beyond Mode generates a structured learning path to fill the gap with vetted external sources.
Quizzes are grounded in your specific resource, not generic topic knowledge. Post-quiz feedback does not just flag wrong answers; it points back to the exact moment in the resource where the concept was covered and tells you how to strengthen it.
Flashcards use the same resource grounding for active recall and spaced repetition.
Mind Maps auto-generate concept graphs from the resource, showing how everything connects, are selectable and queryable via Axiom, and are useful for revision in minutes.
In-video MCQ pop-ups interrupt at identified key moments, reinforcing understanding before confusion has a chance to accumulate.
The Library searches across every session you have ever had: exact video timestamps, highlighted notebook cells, Axiom conversations, quiz results. Pinpoint retrieval, not a semantic search that returns a whole session and leaves you digging.
Students tired of watching tutorials and still not being able to build anything. The gap between understanding while watching and being able to do independently, Last Lab closes it by making execution the default, not an afterthought.
Working professionals who need to stay current but cannot spend evenings on environment configuration. Paste the blog, video, or documentation you want to learn from. The lab is ready in seconds.
Researchers and ML engineers who need to implement papers, especially papers with no existing code, no blog, no walkthrough. TurboQuant is a real example: when tested, there was zero public implementation anywhere. No code, no video, no GitHub. Last Lab implemented it correctly, running, calibrated to your hardware. That gap exists throughout the research community. Last Lab is built specifically to close it.
Teams, institutes, and enterprises that need a consistent, zero-variance learning environment across every member with collaboration mode, role-based access, shared workspaces, and dedicated compute all built in.

It is tempting to look at Last Lab and think: this is just an LLM with a Jupyter kernel attached. It is not.
The engineering is the product. Per-user kernel lifecycle management, isolated execution environments, compute-aware notebook generation, agentic multimodal resource understanding, real-time output streaming, context engineering across parallel downstream artifacts- none of these are prompt engineering problems. They are infrastructure problems that take months to solve and keep surfacing new edge cases at scale.
The reason Last Lab can implement a paper like TurboQuant with zero internet coverage is not that it uses a better model. It is because we built the harness that the model needed to do its job correctly. Equations extracted precisely. Dataset fetched automatically. Environment provisioned for your GPU, not a research lab’s 8xA100 cluster.
That is the difference between a tool that generates code and a platform that guarantees execution. And it is not a difference anyone can replicate by attaching a few features to an existing chatbot.
No setup. No context switching. No forgotten code. Just learning, the way it was always supposed to work.
Turn any video, research paper, documentation, repo, and more into a runnable lab with contextual AI guidance, and zero friction.
Explore Last Lab beyond learning
Join Discord